
What is a key differentiator of conversational AI?
The key differentiating factor when it comes to comparing conversational AI solutions is how accurately they classify intents. The more accurate and reliable the AI, the more powerful the solution that it drives, and the more satisfied your customers. Accurate AI will enable you to serve them exactly the information they’re looking for, reducing frustration and waiting times, and servicing a higher number of incoming queries, much higher than an agent could.
And all of that reflects on your overall customer experience: According to a recent study by researchers at the University of Oslo, efficiency is the number one attribute customers look for in automated support interactions, and the key to effective and efficient conversational AI is – you guessed it, accurate intent classification.
So how can you measure your NLU engine’s accuracy?
To test your AI’s accuracy, you’ll need two things: A set of data to train your AI engine, and samples of natural language that your engine hasn’t interacted with before to run and test its mettle. And that’s exactly what we did with our AI engine in a recent experiment. Read on for a rundown and key results!
Comparing NLU engines: How good a matchmaker is our AI?
The experiment we ran on our NLU engine is based on a previous experiment by Cognigy, which worked like this: Two datasets (one small, one large) were tested using 64 intents to see how reliably their AI model would correctly match these intents with randomly chosen expressions, or sample sentences.
One of the ways to determine accuracy was to look at the number of “false positives” – instances where the AI would incorrectly match random expressions with an intent even though there wasn’t one. The lower the number of false positives, the more accurate the AI model.
For the small data set, Cognigy used 64 intents and 10 randomly chosen expressions to test their NLU, as well as 1,076 example sentences that had not been included in the original training set. For the larger set, they went for 30 expressions and 5,518 example sentences. And we followed suit.
All of these expressions were grammatically correct and the test data set featured short sentences in English with all relevant details to help identify the intent. While this varies slightly from real-life chatbot interactions, which are a little more messy (and international), it still gives us a good idea of the model’s general accuracy.
NLU and AI Metrics: The proof is in the precision
To measure our conversational AI model’s quality, we relied on two metrics: accuracy and the F1 score.
Accuracy refers to the percentage of test sentences correctly matched with the underlying intent. A score of .51 would mean that 51% of sentences were successfully paired to an intent.
F1 is the harmonic mean, or average value, between two additional metrics called precision and recall.
Precision shows us how many expressions that the engine identified were actually relevant to our intent. We measured this by identifying how many of the expressions that the engine marked as “weather-related” were actually weather-related.
Recall shows us the rate of relevant instances that were retrieved: Out of all weather-related queries available in the test data set, how many did the engine correctly pair to a weather-related intent?
Calculating the F1 score let us balance false positives and false negatives, providing an even better benchmarking of the NLU engine by giving equal weight to both precision and recall.
Results: Told ya our conversational AI is the best!
In the table below, you can see how Ultimate’s NLU engine performed on both smaller and larger data sets and how it stacked against other AI engines.
In the table below you can see how Ultimate’s NLU engine performed on both smaller and larger data sets and how it stacked against other engines.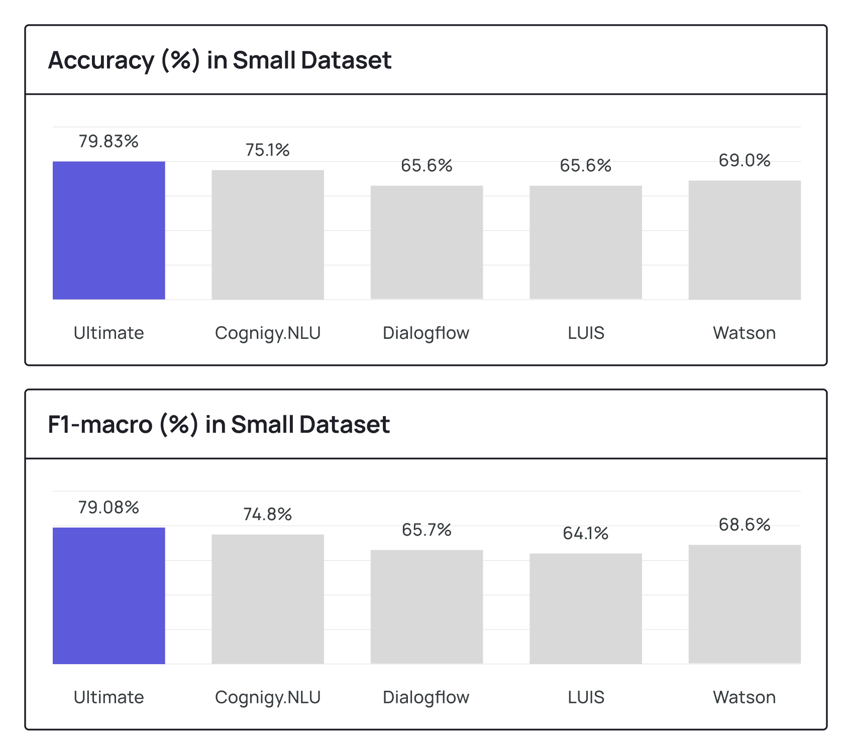
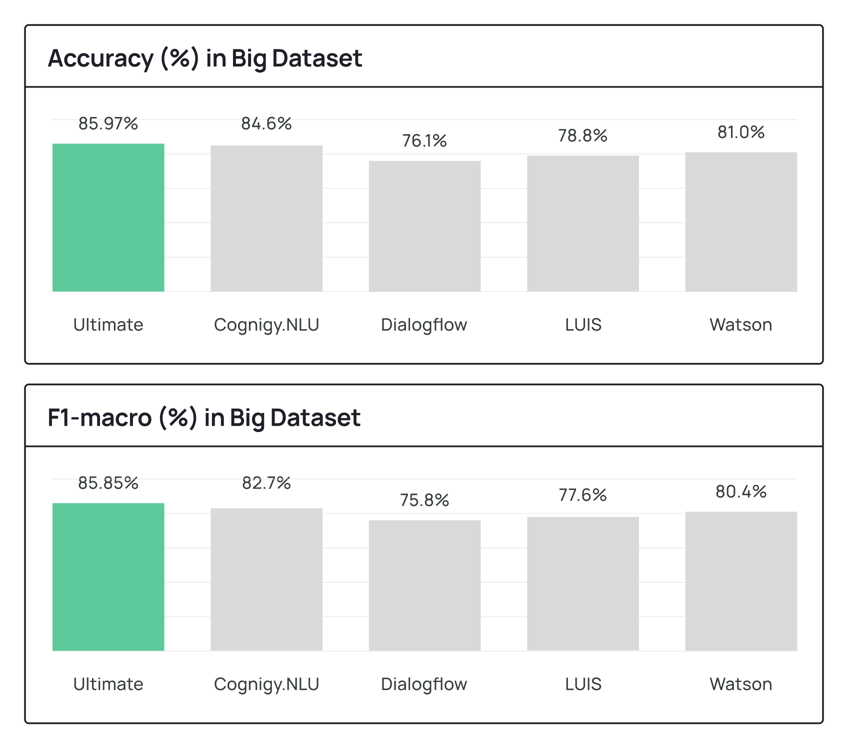
As you’ll see from the tables, it’s clear that Ultimate's NLU engine outperformed all other systems examined.
What should you do with this information?
A reliable AI model is indispensable for creating better and faster customer support with automation – but it’s not the only piece of the puzzle. Having the right team in place to wield conversational AI for maximum value is just as important. Check out our overview of conversational AI here.